

Written by Jared Hillam
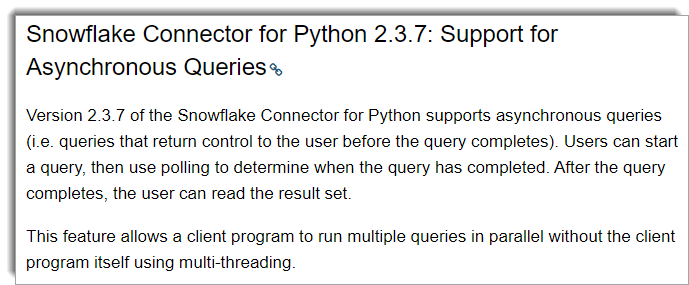
In the December 2020 release notes, Snowflake made mention of a feature that got way too little press. The mention of it was so slight that only hardcore Snowflake aficionados rang alarm bells.
This is probably one of the most understated features Snowflake has ever released and the downstream repercussions of it will reverberate across the entire platform. To understand why, we need to piece apart a Snowflake session, synchronous queries, and asynchronous queries.

The workaround was to open a new session. So the outcome would be the opening of many sessions to execute the queries, which does work, but not without the overhead of opening the sessions themselves. So if you have 100,000 queries those sessions add legitimate overhead. Today DASK managed sessions help smooth out this process to monitor each session and execute the queries. 
100,000 queries?
But wait a second, 100,000 queries? Why would anybody need to fire off that many queries? There’s actually a whole bunch of data-oriented events that could get value from this. First and foremost the data integration pipelines. When data needs to be transformed, imagine being able to execute all the non-dependent queries in a single session (bullet train). In some cases, the impact could be dramatic, as in 50-100X faster. Now think about how fast Snowflake already is at processing data transformations. You get the idea of how incredible this could be. The big one on the horizon is data science and machine learning – more on that later.
This is where Python comes into the picture. Remember the intent is to allow many queries to fire, so it's not like running a query and seeing data. The results are written in Snowflake, if you want to query them you can. Additionally, when asynchronous queries are being orchestrated by Python, Python is in control of the process. 
RESULTS_SCAN... An Annoyance to Feature
-png.png?width=330&name=image%20(7)-png.png) If you’ve ever hated using RESULTS_SCAN, then you’re not alone. Most SQL experts are accustomed to system metadata commands producing queryable results. However, in Snowflake that becomes a two-step process using the SHOW command and the RESULTS_SCAN. What many Snowflake users don’t know is that the RESULT_SCAN turns out to be persisted for every query in Snowflake for 24 hours. So this thing that many SQL experts didn’t like, turns out to be a massive advantage when it comes to programmatic pipelines like the ones created in Python. This is because programmers can leverage the use of query_id’s to drive the “memory” of the application. All Python needs to know from Snowflake is the ID’s of the queries, and leverage Snowflake’s RESULT_SCAN command to execute further events/queries, and that RESULT_SCAN is persisted for 24 hours to be used and reused, as long as the role and user that produced it is running the query. What this also means is that machine learning events and other iterative applications can be wickedly lightweight to process because there’s no moving any data out of Snowflake.
If you’ve ever hated using RESULTS_SCAN, then you’re not alone. Most SQL experts are accustomed to system metadata commands producing queryable results. However, in Snowflake that becomes a two-step process using the SHOW command and the RESULTS_SCAN. What many Snowflake users don’t know is that the RESULT_SCAN turns out to be persisted for every query in Snowflake for 24 hours. So this thing that many SQL experts didn’t like, turns out to be a massive advantage when it comes to programmatic pipelines like the ones created in Python. This is because programmers can leverage the use of query_id’s to drive the “memory” of the application. All Python needs to know from Snowflake is the ID’s of the queries, and leverage Snowflake’s RESULT_SCAN command to execute further events/queries, and that RESULT_SCAN is persisted for 24 hours to be used and reused, as long as the role and user that produced it is running the query. What this also means is that machine learning events and other iterative applications can be wickedly lightweight to process because there’s no moving any data out of Snowflake.
Keeping data inside Snowflake is really what Snowpark is all about. Snowpark is a new developer experience that will enable languages like Python and others to run natively within the Snowflake ecosystem. This means that moving data in and out of Snowflake will become a thing of the past completely because the programming will all run in Snowflake. However, Python developers don’t have to wait for this integration to start natively using the power of asynchronous processing, because the use of the RESULT_SCAN can allow them to internally reference the asynchronous results for up to 24 hours from the date of query execution. If you stand back and think about the RESULT_SCAN, you’ll realize that it essentially is a data frame for everything you have done.
The data science and machine learning opportunities are an obvious application for asynchronous jobs. Snowflake today is processing data science workloads via DASK managed sessions or they’re extracting the data out into data frames and processing them externally to Snowflake. Enriching the ability to add N queries to sessions will greatly increase the speed of broad execution, giving a yet lower grain of processing power in each session AND leave it in Snowflake. Support for this will likely take some time to come to the native DASK frameworks, but Python developers can execute that control directly today.
This isn't the "bunny hill"
Let’s make one thing clear. This is a very advanced approach to using Snowflake. Users have to understand the pipelines from end to end so they know which queries can independently run and which have a dependency to be met. On top of that, they need to understand that they are orchestrating that entire process and there are fewer guard rails in the mix. But additionally, it's also clear that the efficiency opportunities are massive. While the use of asynchronous queries isn’t for your average developer, Intricity can help in the adoption of it.

While the December 2020 announcement was easy to look over, it was the seed to a massive branch of Snowflake’s future compute usage. Python support for this functionality is only the beginning as other programming languages and drivers will be able to dip into this power.
Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
