

Written by Jared Hillam

Late last year, Snowflake introduced Snowpark which opened support for a wider array of development languages like Java, Scala, and Python. This broader support will most certainly spur application innovations on the Snowflake platform. But one thing that application developers need to understand is that Snowflake is a semi, not a motorcycle... Huh?
Most application developers are accustomed to wiring up their applications to read and write singular records. Databases such as NoSQL and traditional OLTP are well-suited to deliver on that methodology. Everything, from the core database code to the schema of the database, is designed to optimize for many singular insert, update, and delete events.

Just because these events are small, it doesn't mean the audience executing those events is small. That audience could be (and often is) huge. However, the central assumption in these transaction-oriented systems is that the audience's individual interactions will be small. In other words, we won't have a user running a massive data query or data load. When that does occur the database gets pushed over the edge. Regardless whether this is an application written in the cloud or on prem, the transaction-oriented database will struggle to produce the query results. In the past, when compute was not segregated, it meant that the application would become extremely slow for the users. This is still the case in some application systems.

Even if you do have segregated compute, a transaction-oriented database will struggle to return bulk query results, as it goes against the grain of how its foundations are designed (and we'll delve into this later). Just like a motorcycle isn't designed for moving hundreds of packages at a time. Would it be possible? Sure, but it would be very, very slow to execute. However a motorcycle is a great way of moving a few pizzas around and is definitely more agile for quick trips.  So you can think of these little insert, update, and delete commands like a bunch of little motorcycles zipping around, but the moment we request that all the packages go on 1 motorcycle things get really slow.
So you can think of these little insert, update, and delete commands like a bunch of little motorcycles zipping around, but the moment we request that all the packages go on 1 motorcycle things get really slow.
This is why MPP databases became a thing. They provide a redesigned foundation for effectively handling bulk data requests. Originally, this was done by giving each hard drive its own processor so they could handle faster inputs and outputs in singular queries, the innovations started in the late 1990's and continued till what we have in Snowflake today. But make no mistake, Snowflake is a completely different animal. For a refresher on how different Snowflake is, I recommend checking out some of our earlier white papers:
- What is Snowflake?
- Why a "Snowflake Killer" is so Hard?
- How to Botch a Snowflake Deployment in 3 Easy Steps
To put it bluntly, little reads and writes on Snowflake will be... slow. If you had to replace a transaction database with Snowflake it would perform abysmally. Snowflake doesn't hide that fact either. All the architectural gymnastics that Snowflake does to create an amazing data platform experience are just overhead for tiny read/write events. So when programmers are looking at new opportunities to leverage Snowpark to make the next cool app, they need to think of Snowflake as a fast semi not a motorcycle. It will move a ton of packages really fast. But it won't perform well for pizza delivery.

But Why?
Let's explore the specific reasons why this is the case.
Columnar
Like other MMP data stores, records in Snowflake follow a columnar form. What this means is that the records are written for all the values in a singe column, before writing to the next column. So if I had dates for US Presidents the raw data would be written like this:
2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, Barack Obama, Barack Obama, Barack Obama, Barack Obama, Barack Obama, Barack Obama, Donald J. Trump, Donald J. Trump, Donald J. Trump, Donald J. Trump, Democrat, Democrat, Democrat, Democrat, Democrat, Democrat, Republican, Republican, Republican, Republican
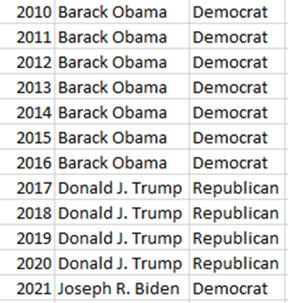 We don't tend to think in terms of columns; we think of things in the form of events (rows). But it's not as foreign as you might think, because our brains scan the same way. While you look at the table here, watch your brain as you answer this question. Which years was Donald J. Trump president? Unless you're an odd duck, you likely didn't scan row by row from left to right, top to bottom, until the end. You scanned the President's column and then looked over at the dates. A column store essentially does the same thing by storing the data in a column based sequence.
We don't tend to think in terms of columns; we think of things in the form of events (rows). But it's not as foreign as you might think, because our brains scan the same way. While you look at the table here, watch your brain as you answer this question. Which years was Donald J. Trump president? Unless you're an odd duck, you likely didn't scan row by row from left to right, top to bottom, until the end. You scanned the President's column and then looked over at the dates. A column store essentially does the same thing by storing the data in a column based sequence.
So why is this bad for singular transactions? Well... try it. Add the following new record to the column based sequence:
Add the New Record Below
2021, Joseph R. Biden, Democrat

2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, Barack Obama, Barack Obama, Barack Obama, Barack Obama, Barack Obama, Barack Obama, Donald J. Trump, Donald J. Trump, Donald J. Trump, Donald J. Trump, Democrat, Democrat, Democrat, Democrat, Democrat, Democrat, Republican, Republican, Republican, Republican
Notice you're having to scan the data all the way through to see where you need to inject each field. Annoying and slow, it would be far easier to just write it natively as:
2021, Joseph R. Biden, Democrat
Micro-Partitions on Immutable Storage
When data is loaded into Snowflake, the target deep down is either AWS S3, Azure Blob, or GCP Storage. These storage layers have the distinct trait of being unchanging. Once a record is written in, it's there "forever" (yes, a hard delete is possible).
The combination of micro-partitions and immutable storage are the secret sauce for how Snowflake is so incredibly fast at dealing with such large quantities of data. The micro-partitions are like "bins" which Snowflake uses to minimize wasted scanning cycles which makes big queries really fast. 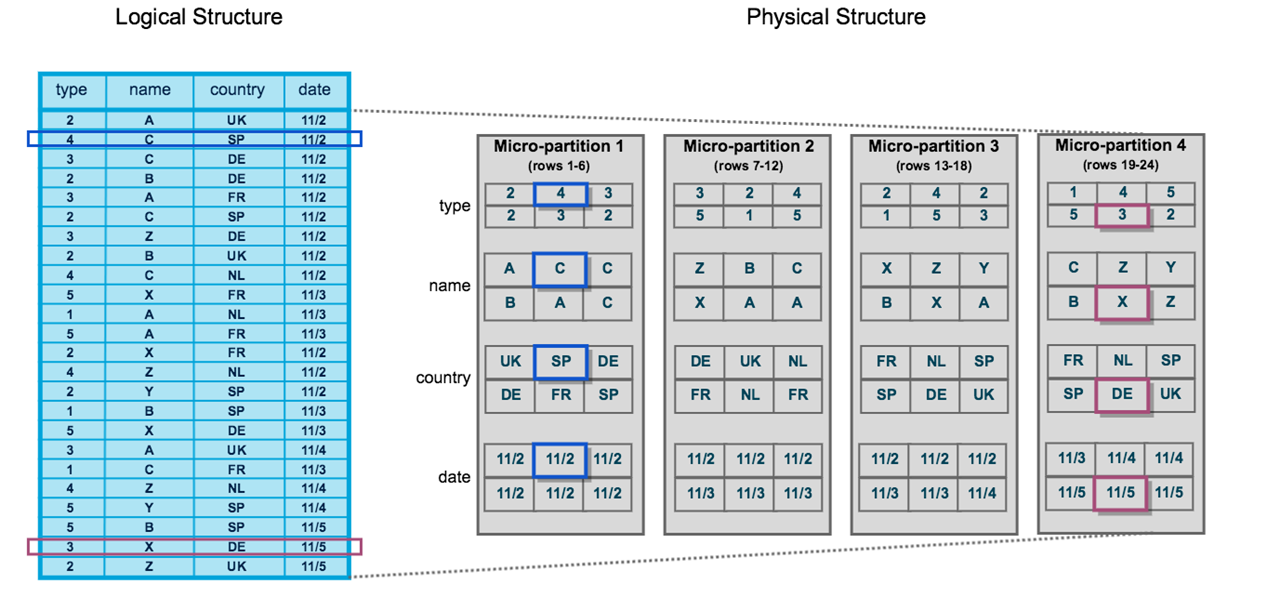
However, for a transaction-system they further the demise of performance of tiny inserts, updates, and deletes.
To explain, let's talk about how you might use a simple form on an application. You first may insert your email address and name. Then at a later point, you come in and provide a physical address, then you add your phone number, then you go back to fix your email because it was entered wrong. Then over time you delete the phone number because it's no longer current. This is all normal behavior and user communities are conducting these kinds of inserts, updates, and deletes all day long.
With each insert, update, and delete, the changes are simply added as new immutable records and are ultimately "binned" in the micro-partitions. Whatever old metadata pointers were pointing to the prior record set got deleted in favor of the updated metadata pointing to the new records. OK, box that up for a minute, and we'll unpack it later.

If you remember back in the late 90's and early 2000's, it was common to need to defragment your hard drive. The reason you had to do that is because files were physically strewn across the hard drive in separate locations. So when files or applications needed to be opened, it would have to navigate up and down the hard drive platter to capture all the data you needed. This would cause the execution of your hard drive to be very slow over time. The solution was to reorder the allocated spaces on the hard drive to related files so access time would decrease. For some, this solution would completely revive the computer and it would perform like new.
Now lets unpack our micro-partition discussion. Micro-partitions behave in a very similar way to the allocated spaces on a hard drive. Imagine a record undergoing a handful of inserts, updates, and deletes over the course of a year. The record would be fragmented across many micro-partitions. So even a basic record read would require multiple micro-partitions to be opened to capture everything. This happens in analytical scenarios when things like blind updates or careless loading of Snowflake takes place. Organizations can end up needing to scan a host of micro-partitions to acquire a result set because the column values cannot be found in a single place. In the example below you'll see columnar record set of CD_EDUCATION_STATUS strewn across 21,742 micro-partitions, and overlapping multiple micro-partitions. But after being auto-clustered (like defragmentation), the number plummeted to barely over 1 micro-partition with almost no overlap.
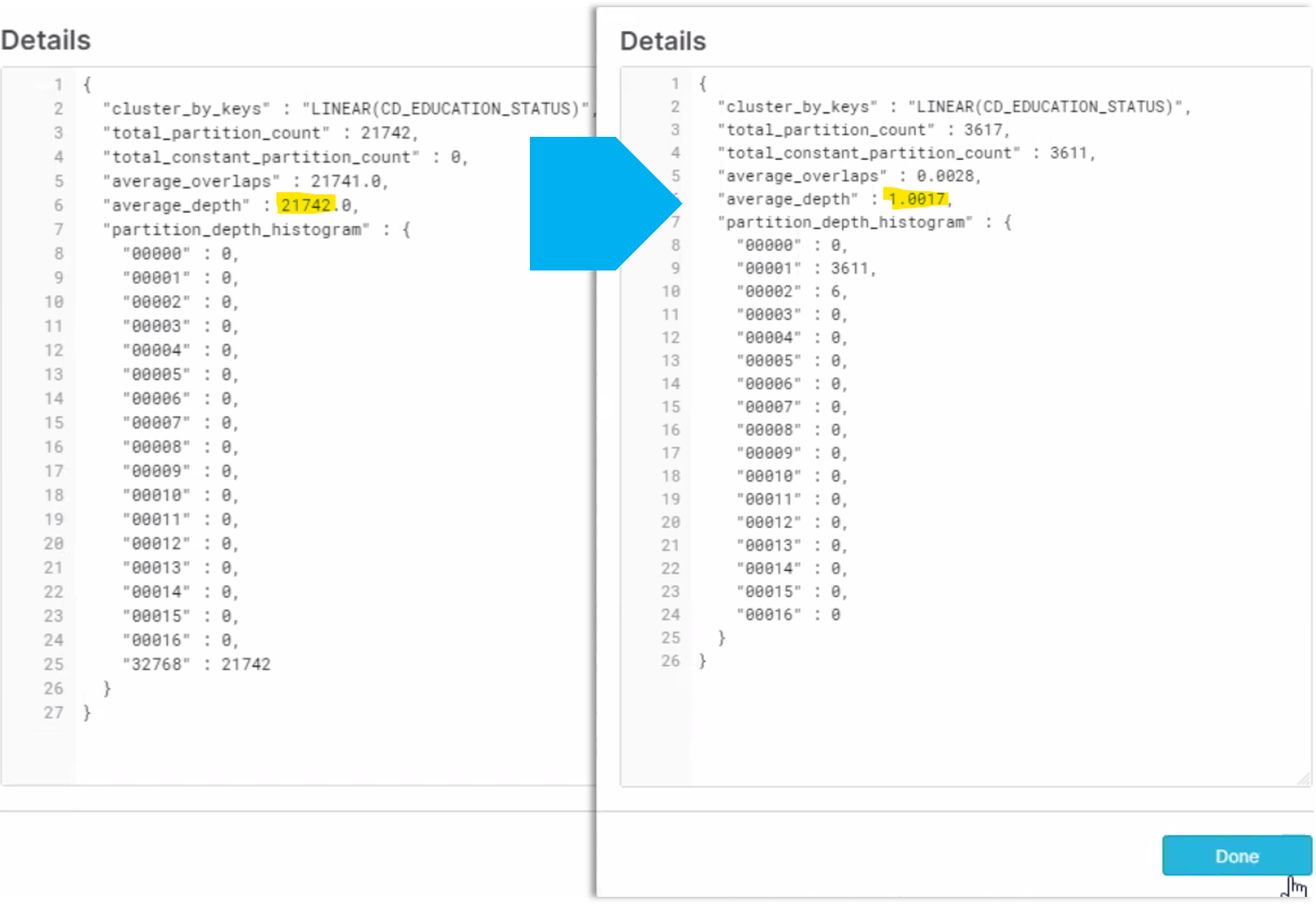
Obviously auto-clustering is a good remedy for defragmenting records, but it requires compute to execute, so it's not necessarily cheap to do. If records were being written one-row mapped to a column one at a time, things would become fragmented really quickly. In analytical use cases, even a fragmented Snowflake instance still works reasonably fast (don't forget its capturing and computing millions of records in one go). However, if it is only dealing with 1 record, this fragmented scanning will be very slow for little payback.
Ergo
To most data architects, this Frankenstein scenario of using Snowflake as a transaction-oriented database doesn't even need an explanation. But to application developers, that don't spend their day with bulk data engineering, this might not be so obvious. Snowpark is going to be a super exciting endeavor, and for the right use cases, it will be game changing. Application developers just need to remember, Snowflake is a fast semi-truck and not a pizza delivery motorcycle.
Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
