

Written by Jared Hillam

Totalitarianism and Anarchy
If we were to take the two extremes of Governance, we would have a spectrum of Totalitarianism and Anarchy. But when it comes to managing data, neither of these two extremes really exist. What we often find with organizations is that they are struggling to define how they are going to provide some order to their data. After all, their data already is in a very chaotic state. The chaos comes from the constant inflow of data from dozens, if not hundreds, of data sources. Determining what that data is and trying to do something useful with it, often is the genesis of getting an organization to recognize that some governance is necessary.
 |
||
| A system of government that is centralized and dictatorial and requires complete subservience to the state. | A state of disorder due to absence or nonrecognition of authority. | |
The Spectrum of Totalitarianism
Advantages
There are some distinct advantages to centralizing the data governance effort. First, in order to scalably feed data to the the entire organization, and have that data be reliable, we need to have rules that are consistent and centralized. After all, if we’re measuring performance, we’ll need some consistency. One thing that management members can’t stand is multiple versions of the truth. Because it provides an “out” for non-performance.  Additionally, the organization needs to be able to manage itself in relation to a mission statement or collective outcome.
Additionally, the organization needs to be able to manage itself in relation to a mission statement or collective outcome.
So let's talk about a tactical scenario. Imagine the sales department categorizes a shipment date as the day the item arrives at the customer's location. But then let's look at the Shipping Department, they categorize their shipping date as the date it left the dock. Now let's go to the same meeting, and look at their siloed reports. Let’s imagine that they’re having issues with their shipments arriving on time. The Shipment Department analyst brings his report and the Sales Analyst brings her report. Now things get even more confusing because the shipment dates for the item ID’s don’t match at all. Nobody's quite sure but clearly something is wrong. They discuss the problem but they can’t point to any tangible shipments to change behavior internally. So they break the meeting with no behavioral change. Can you see how this could create a mess to manage? These meetings happen all the time, and often there’s not enough awareness about the data to really say where the discrepancies are.

So not only are the definitions of data important, but so is the consistency of data across systems. So let's imagine you have Salesforce.com for your CRM. Does your SAP ERP know that you have Salesforce.com? Does your ServiceNow ticketing system know you’re using Salesforce.com? Do the data systems from your last acquisition know you’re using Salesforce.com? Of course not, NONE of these systems are necessarily aware of each other's operation. So when a customer is interacting with your company, you may have dozens of versions of that customer all sitting in different systems in your organization. Solving this problem is not a little task. It requires machine learning, process changes, rules for data updates, and potentially 3rd party data enrichment. All this takes a coordinated team of people with an outlined goal and process framework.
Totalitarianism’s Head Start
One particular advantage that the top down governance has had is in available tools. Almost every tool over the last 10 years to address Master Data Management, Data Quality, Data Catalogs, and Metadata Management, has been of the “big budget” variety. Each one of these tools starts with the “Big IT” base assumption. Why? I believe there are 4 reasons for this:
- Business Intelligence and ETL tools were traditionally an enterprise wide purchasing decision, so whatever data went into those tools was managed by a centralized team
- The cost of Data Governance tools like Master Data Management and Data Quality have traditionally been too high for individuals to include in their budgets, but they were something the CIO or CFO could afford
- Getting people to add Data Governance tasks to their list of to-do’s was something that often had to come from the top down
- The complexity of managing data grows the more you centralize and conform it, thus it was an intimidating prospect for individuals to take on
Disadvantages
Centralized Data Governance is plagued with a number of disadvantages.
One major disadvantage is the lack of buy in from the broader organization. Often management members bring their best intentions to their business users, and try to get them excited about participating in managing data. But the reality is, most business users don't care enough about upper management’s data quality issues to really include it on their daily to-do’s.
So most data governance meetings often turn into what I like to call “donut meetings”. Nothing really gets done but everybody gets a donut. But business users aren’t the only ones that ignore the problem, Upper Management themselves struggle to understand the ROI on trusted data, because it's something they aren’t faced with every day.
This ultimately leaves middle management members scurrying to play the cat herder role. The pressure for middle management is really on, if the organization has invested in an expensive Master Data Management solution. So often we find organizations scheming for carrots and sticks to get their business users and upper management to put some skin in the game. Part of the problem is that business users themselves don't perceive themselves as having a problem at all. Data quality is “somebody else's problem.“
Data’s Black Market
When I lay out a spectrum of the two governing extremes I often ask.”Where would you put your company?” Most would give a sigh and say “we’re totally a mess it's anarchy man.”

And I seem to get this answer whether the company has invested millions of dollars in Master Data Management or not. What's likely happening here is that your company has some kind of program for creating a centralized “trusted” data store… and nobody uses it.
I refer to that as a “Black Market”. Meaning data is provisioned and some governance has been provided, but users know they can get the “good stuff” elsewhere. The incentives for people to create a black market run the gamut. Like:
- “I don’t want to lose my job”
- “IT doesn’t know what it’s doing”
- “That’s not actually how it works”
- ”It takes forever to do it the new way”
The Black Market is definitely one of the challenges in having a centralized data governance process. Management thinks that they’ve solved the problem, but in reality people are just circumventing the process controls to “get $#!t done”.
Complexity
The more data comes together to represent a single version of the truth, the greater the level of complexity becomes to get agreement across users and data logic assembled. This is particularly the case in unifying metadata and master data. So a tremendous level of fragility begins to build the more top heavy the master data logic becomes. Suddenly the expensive Master Data Management tool needs an equally expensive team of Data Governance & Stewardship headcount in order to keep up with the ever nuanced rules for managing data.

The relationship between the level of complexity and fragility is something well explored in Nassim Taleb’s series of books called Incerto. https://www.amazon.com/Nassim-Nicholas-Taleb/e/B000APVZ7W
The Spectrum of Anarchy

It would seem that anarchy would not even have a representative group, but it's important to realize that this group has only existed over the last 4 years. So I'm going to take you on the journey of how this group emerged into existence.
The Advent of the Power User

In the early 2000s, business intelligence was something that was really only available through large Enterprise purchases. Outside of that platform, data consumers were relegated to using Excel. But in the last 4 years, we've seen those users of excel adopt some pretty amazing visualization tools. The users of these tools easily got the attention in corporate meetings because the analytic views were far more functional and visually appealing. This appeal became a huge draw and suddenly corporations were looking at the prospect of buying personal analytic tools for their entire Enterprise. The challenge with these tools is that conforming the data before it got analyzed was a real hassle. Users would have to spend almost half of their time doing data prep, so the process was not that much different than doing all the work in Excel, but the results were far more visually appealing. With the user community growing so fast within many corporations, the market began to emerge for self service data quality. These tools enabled users to conduct common yet complex data conformity exercises which would take a lot of time to do manually in Excel. The industry now calls this task data wrangling. What this means is that the masses are far more enabled than they were in the past, and in some cases their data quality changes are far more accurate than the centralized and sanctioned top-down effort. 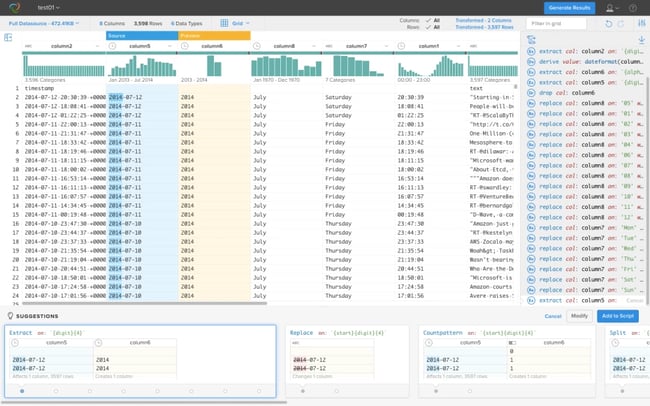 This is because the people doing the data cleansing were often the business users themselves. More importantly, these data wrangling tools enabled users to create data quality recipes which could be published and shared between users. Thus simulating the centralized efforts of the totalitarian style of data governance program.
This is because the people doing the data cleansing were often the business users themselves. More importantly, these data wrangling tools enabled users to create data quality recipes which could be published and shared between users. Thus simulating the centralized efforts of the totalitarian style of data governance program.
Along with these tools for cleansing the data, additional tools came out for helping users create effective data catalogs. This is because users found it frustrating to attempt to 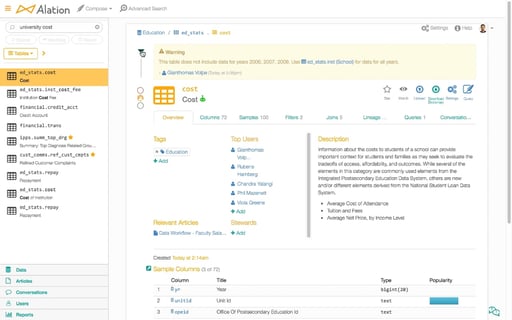 navigate the complex data structures within a corporation. In the past, this kind of knowledge was locked in the minds of only a few technical power users. However, these data catalogs and tools enabled data visualization analysts to engage in creating a Yelp-style glossary of data with rich context on who is using what and where it's being used, thus enabling the masses to work more like a collective.
navigate the complex data structures within a corporation. In the past, this kind of knowledge was locked in the minds of only a few technical power users. However, these data catalogs and tools enabled data visualization analysts to engage in creating a Yelp-style glossary of data with rich context on who is using what and where it's being used, thus enabling the masses to work more like a collective.
Advantages
Giving the masses the power to do their own analytics means that they also have their own incentives to ensure that the data is clean. In other words, they have skin in the game, and they understand why clean data matters. Additionally, they tend to look at their processes and the data generated by those processes with a lot more reverence. They know that entering in the wrong data or using a field incorrectly will have bad downstream effects when they go to analyze the data. Simply put they are closer to the problem.
Another clear advantage is speed. When a business user is enabled with analytics they are also in charge of their own destiny. Business users usually don’t trust IT to field their request for information. However, if they are in control they can also set the priority of how urgently they need an answer to their question.
Disadvantages
Anarchy has a lot of disadvantages, partially due to how young the tooling is for such a governance approach, but largely due to the nature of the data governance problem.
Everything’s a Nail
Enabled business users (or power users) know they can produce analytics in their particular sphere of complexity. However, they often have a “everything's a nail” mentality to corporate wide data integration and governance. So they often lack the appreciation for how important corporate wide conformed data is, because they are working in the context of a specific application. This also means that they are often unaware that their data is incorrect because it doesn’t take into account another set of application data.
are working in the context of a specific application. This also means that they are often unaware that their data is incorrect because it doesn’t take into account another set of application data.
Inconsistency
The disconnected nature of Anarchy means that organizations will often have individuals repeating tasks which others have already done. The sharing of data cleansing recipes most definitely helps tamper this issue, but because users still have the autonomy to add more or less cleansing to the data, variability across users will always be present.
Multiple Versions of the Truth
When data ultimately needs to be used for executive management decisions, Anarchy can be very frustrating indeed. With so many carrying their own analytics, it can be difficult to determine who indeed has the correct perspective on the corporate data.
My Baby!
Often when power users have spent countless hours cleansing and conforming data for their visualizations, it becomes their “baby.” Particularly when others see value in its output. And in those cases it creates an incentive to treat their work as secret sauce and is their perceived ticket to job security. This also means that the larger corporation often becomes starved for reusable information.
You Can Choose
You don’t have to just dumbly land in Anarchy or Totalitarianism. This can be an engineered choice. However, it requires you to take a serious look at the People, Process, Technology, AND culture of your organization (see our whitepaper about that topic).
Intricity can help you come up with a strategy on how to roll out a data governance program, and balance the right components to effectively tackle the problem head on. I’ve never seen utopia in Data Governance. I’ve only seen trying and not trying. If you make a conscious decision towards either side of the spectrum then you can at least be prepared to deal with the disadvantages and tooling to successfully navigate future.
I recommend you reach out to Intricity and talk with a specialist about your current challenges. We can help you come up with a strategy and roadmap that can break down the effort into budgetable chunks.
Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
